React 核心原理:Fiber架构、调度机制与Hook实现
June 23, 2024 (2y ago)
对React 使用到了一定的程度 之后,你应该好好的学习一下它的底层实现原理了(如果你一直在使用React 那么你绝对需要的),课程来自 卡神的 解析 React技术揭秘自顶向下学 React 源码 - 思否编程 - 学编程,来思否,升职加薪快人一步
理念
React的定位是一个“快速响应的UI库 而不是大一桶的框架”,关键字:“快速响应就要克服(CPU/IO 瓶颈)“,
- CPU瓶颈
主流浏览器帧数为 60FPS,也就是 16.6ms 一帧,如果这一帧 JS执行过长会而渲染没有跟上,会导致渲染不流畅。一般的解决是 防抖和截流(本质上都是限制我们更新的频率,而且体验不好 掉帧),React最新版本解决方案:异步可中断的更新
- IO瓶颈
将人际交互的结果 应用到UI中,去掉过多的 中间loading 状态,让用户感知不到loading....(在某些方案). 这个是之前的方案,目前React 已经推出的新的技术 “异步的可中断的更新”
新的老的架构
主要来唠嗑一下新的 vs 老的 的特点和工作流程
React的旧版本架构:两层设计 协调器(什么组件需要渲染 ) Reconciler(找变化) / 渲染器 Render(执行渲染)
一个最简单的例子如下:

如果在React15 发生了 “更新中断”会导致BUG

React的新版本的架构:Scheduler(调度器 调度任务的优先级,高优任务优先进入Reconciler) + Reconciler + Render;
Reconciler的工作大概工作流程,render的大致工作流程,
可中断的循环过程。React16 下的 State是如何更新的?

Reconciler内部采用了Fiber的架构,15老的架构就是同步更新的做法,16之后的就是“可中断的异步更新”
Fiber的架构的实现原理
代数效应(Algebraic Effects 主要的目的就是把副作用分离),和函数式编程的复习;
纤程与进程(Process)线程(Thread)协程(Coroutine js中已经有实现了generate)同为程序的执行过程,Fiber的含义有三,作为架构,作为数据结构 ,作为动态的工作单元。用return指代父级节点。
优先级的要点:更新可以中断,高优先级可以取代低优先级 先更新
Fiber架构的工作原理
Fieber
在内存中直接构建tree并直接替换的技术=双缓冲技术(React使用“双缓存”来完成Fiber树的构建与替换——对应着DOM树的创建与更新。
新fiber和旧fiber通过 属性 alternate 进行连接
current Fiber tree <- alternate -> workInProgress tree,
以下是一个简单的fiber例子
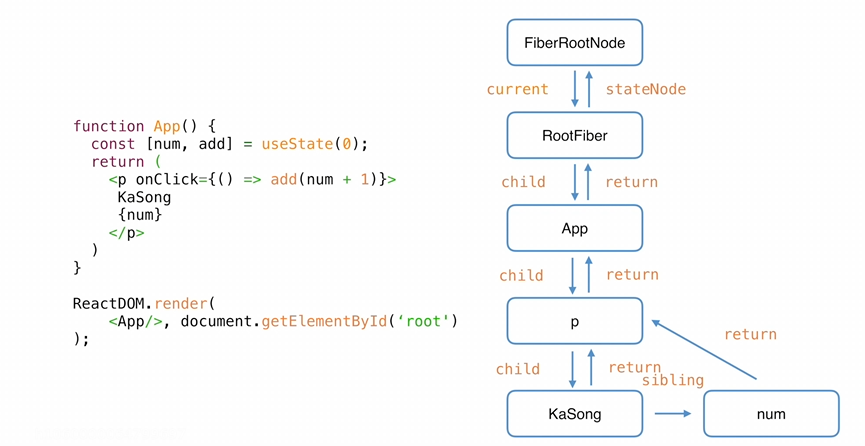
关于fiber的数据结构如下:
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
// 作为静态数据结构的属性
// Fiber对应组件的类型 Function/Class/Host...
this.tag = tag;
// key属性
this.key = key;
// 大部分情况同type,某些情况不同,比如FunctionComponent使用React.memo包裹
this.elementType = null;
// 对于 FunctionComponent,指函数本身,对于ClassComponent,指class,对于HostComponent,指DOM节点tagName
this.type = null;
// Fiber对应的真实DOM节点
this.stateNode = null;
// 用于连接其他Fiber节点形成Fiber树
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
// 作为动态的工作单元的属性
// 保存本次更新造成的状态改变相关信息
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
// 保存本次更新会造成的DOM操作
this.effectTag = NoEffect;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// 指向该fiber在另一次更新时对应的fiber
this.alternate = null;
}一个简单的 mount 和update的流程介绍,对于新的架构我们有如下的几个重要概念
- Scheduler 和task 调度优先级相关
- Recociler 工作阶段被称为rendr阶段,在这个阶段调用 render方法
- Render 被称为 commit 阶段,它会把render 阶段提交过来的东西 渲染出去
- 上面的阶段 统称为work
React源代码的目录结构及调试
如何在本地构建ReactLib?
首先你需要了解yarn link 操作:
当你在Yarn包管理器中运行yarn link时,它会在包目录中创建一个符号链接。这在开发过程中很有用,当你想要在另一个项目的上下文中测试对一个包的更改时,而不必将该包发布到注册表中。链接的包然后在项目中被用作常规依赖项。
如果你想还原回去,可以参考下面的步骤:
- yarn 还原
# yarn 还原
$ yarn unlink
# 卸载本地项目包
$ yarn remove package-name
# 重新安装包
$ yarn add package-name然后我们再来讲 如何把react拉到本地进行构建和build 以及link。
# git clone react
git clone https://github.com/facebook/react.git
# yarn & build 打包成cjs版本 然后link到yarn本地
cd react
yarn
yarn build react/index,react/jsx,react-dom/index,scheduler --type=NODE
cd build/node_modules/react
# 申明react指向
yarn link
cd build/node_modules/react-dom
# 申明react-dom指向
yarn link
# create 一个react项目,并且check一下看看是否连接到本队的react 了去了
npx create-react-app a-react-demo
cd a-react-demo
yarn link eact react-dom
# 大部分同学应该都执行不了上面的全流程,所以这里给一个卡老师的构建好的包 直接去yarn link吧
git clone https://gitee.com/kasong/react
源码目录和关键点:
根目录
├── fixtures # 包含一些给贡献者准备的小型 React 测试项目
├── packages # 包含元数据(比如 package.json)和 React 仓库中所有 package 的源码(子目录 src)
├── scripts # 各种工具链的脚本,比如git、jest、eslint等下面的是从 package react中来的
- React.createElement
- React.Component
- React.Children
这些 API 是全平台通用的,它不包含ReactDOM、ReactNative等平台特定的代码。在 NPM 上作为单独的一个包发布。
- Scheduler
- react-reconciler
react-server # 创建自定义SSR流
- react-client # 创建自定义的流
- react-fetch # 用于数据请求
- react-interactions # 用于测试交互相关的内部特性,比如React的事件模型
- react-reconciler # Reconciler的实现,你可以用他构建自己的Renderer- react-art
- react-dom # 注意这同时是DOM和SSR(服务端渲染)的入口
- react-native-renderer
- react-noop-renderer # 用于debug fiber(后面会介绍fiber)
- react-test-renderer我们需要关注三个重点的地方:Scheduler - Reconciler - Render;
Reconciler 是我们核心的重点,它链接两头,一边是Scheduler 一边是 Render,React的源码如何获取以及如何进行有效的调试?yarn的命令操作有哪些?
关于JSX
JSX会被默认编译成 React.createElement 调用
ClassComponent 和 FunctionComponent 都是 react comopnent,对他们的instanceof Function = true 都是一样的结构,React 内部使用 isReactComponent 来判断 看看到底是不是 classComponent
JSX 仅仅是一个描述性质的数据结构 并不包含 scheduler reconciler render相关的信息
export function createElement(type, config, children) {
}
- 参数1 具备真实DOM 的type 叫做hostComponnet, 对于Class 传递的就是Class
- 参数2 props
- 参数3 children
- React.createElement 这个funcion的流程
{
check一些通用的config
let propName;
const props = {};
let key = null;
let ref = null;
let self = null;
let source = null;
if (config != null) {
if (hasValidRef(config)) {
ref = config.ref;
// ++++
}
if (hasValidKey(config)) {
if (__DEV__) {
checkKeyStringCoercion(config.key);
}
key = '' + config.key;
// ++++
}
for (propName in config) {
if (
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// ++++
// Resolve default props 处理保留属性
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
//处理defalutProps
props[propName] = defaultProps[propName];
}
}
}
if (__DEV__) {
if (key || ref) {
const displayName =
typeof type === 'function'
? type.displayName || type.name || 'Unknown'
: type;
if (key) {
defineKeyPropWarningGetter(props, displayName);
}
if (ref) {
defineRefPropWarningGetter(props, displayName);
}
}
}
// 最终返回一个 element 调用 这个调用会返回 一个element对象,
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
function ReactElement(type, key, ref, self, source, owner, props) {
const element = {
// This tag allows us to uniquely identify this as a React Element
$$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner,
};
//++++++
return element
}
关注一个属性 "$$type === REACT_ELEMET_TYPE" 看看是不是合法的rect elememt
通过一个修改知乎 的所有dom 例子,来理解createElememt ,详见文章:
Q&A:
什么是?react elemt functon (Elelemt返回出来的东西)
react Compoent 有两种 (Function / Class),它们都是react componnet, componet作为createEletm的第一个参数,jsx 和fiber的关系:fiber 组件创建的依据就是jsx数据结构信息,fiber通过 function createFiberFomrElememnt构建
Render阶段
这里采取的算法是 :“深度优先”
整体的流程大概的样貌
我们通过 运行一个 react项目,然后从chrome的js执行堆栈中 可以清晰的看到 ,react的运行的阶段。
创建rootFiber
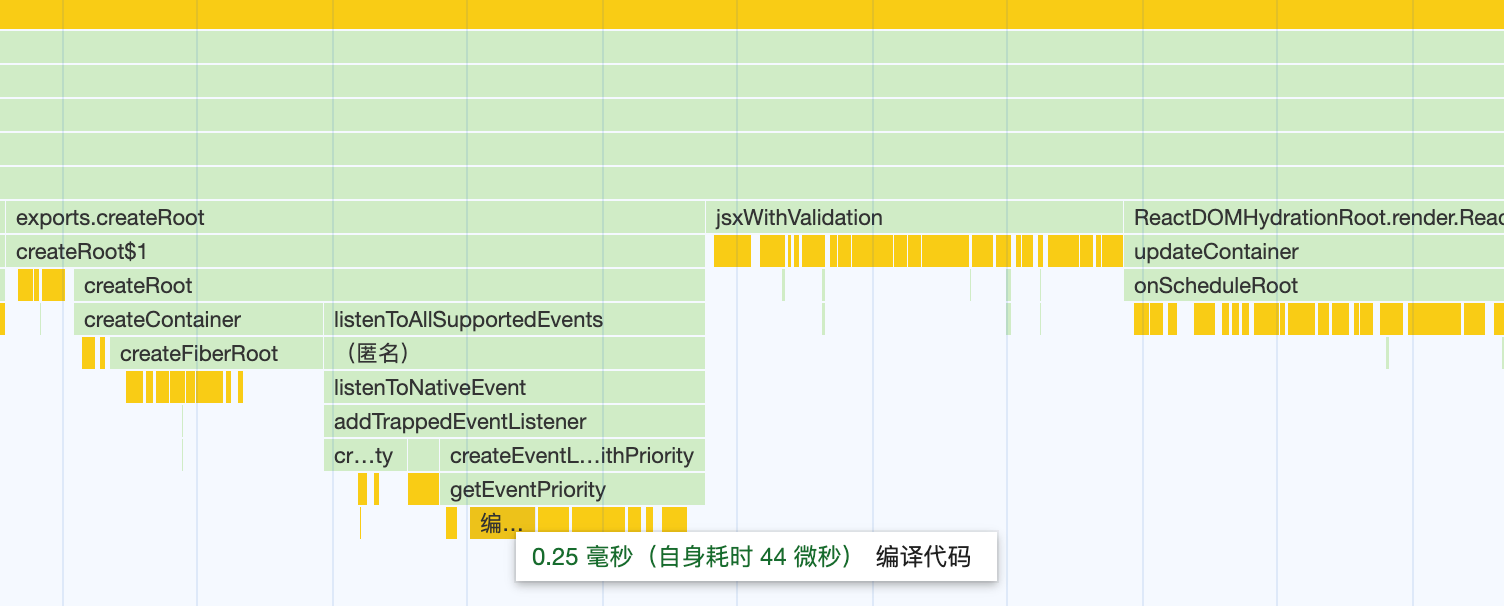
执行一下render - schudelr 也在这个阶段执行
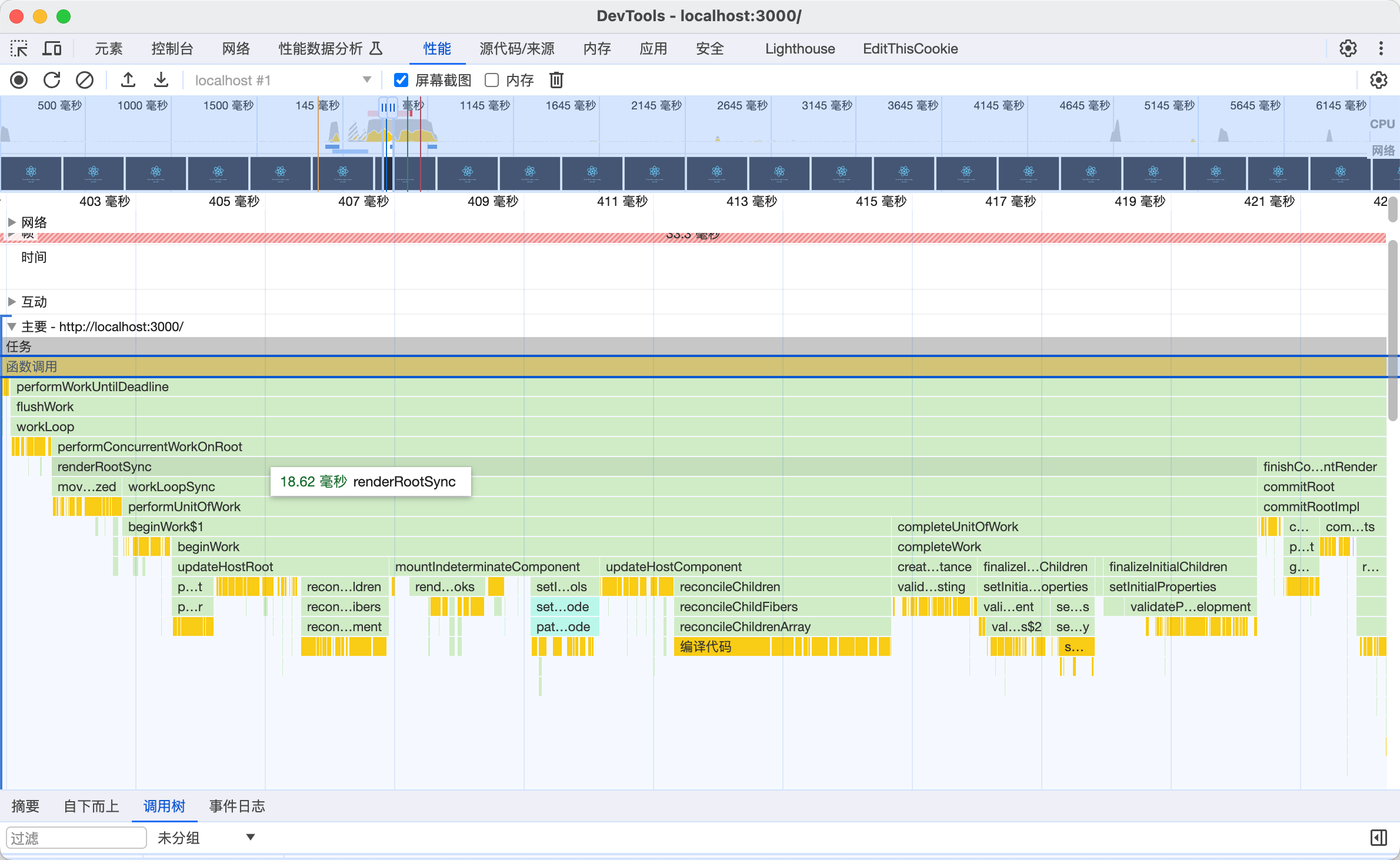
执行后续的comit
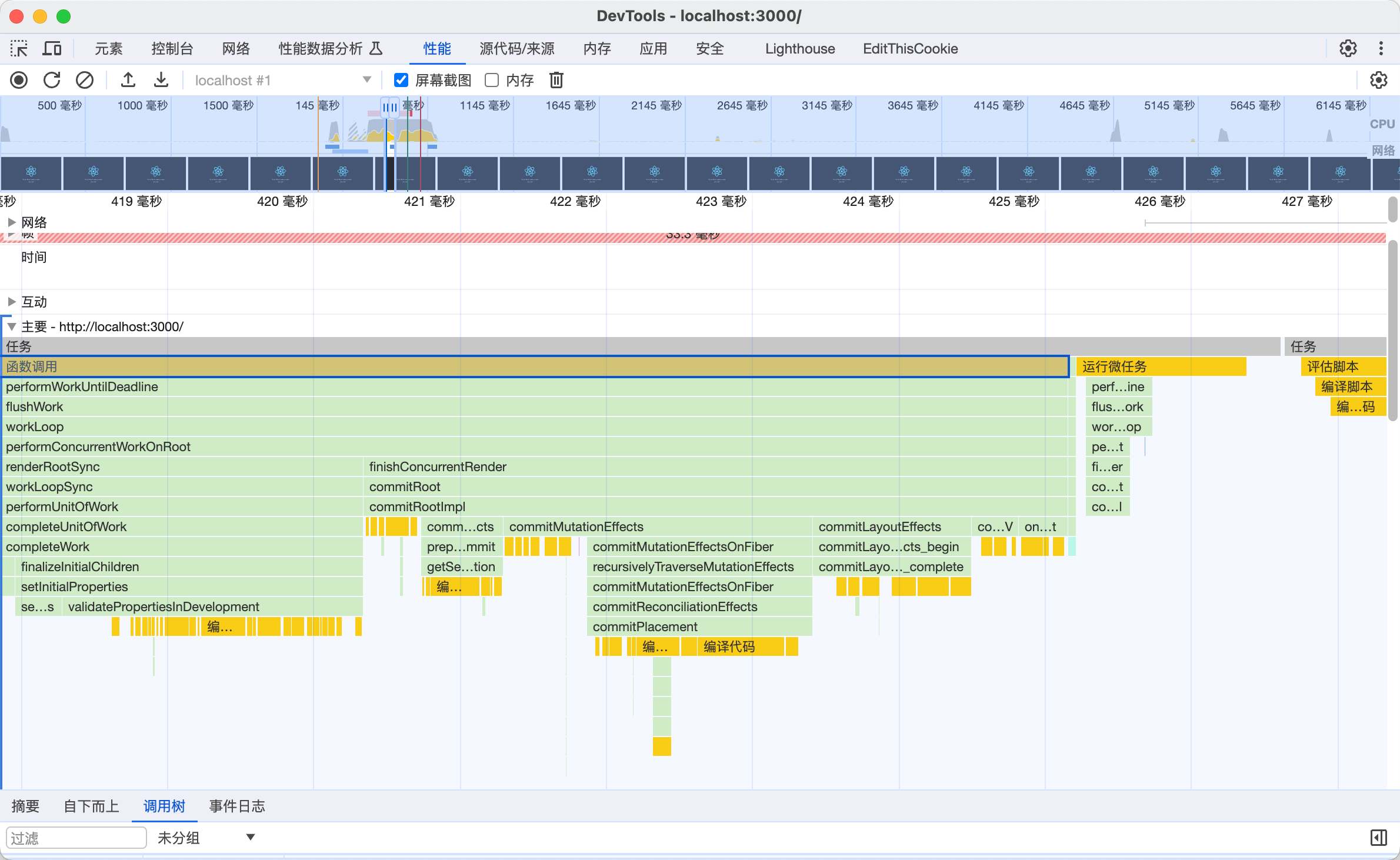
主要分三个部分的调用栈
- 创建应用根节点 创建rootFiber阶段
- redner阶段 调度完之后就执行更新,递归两个阶段 beginWork/CompoletWork
- comit阶段,完了之后 就是comit 渲染到page上
Fiber 架构
在React16 架构中 虚拟DMO = Fiber ,异步的可中断的更新。
React15 是递归的做法导致性能不足;Fiber的三层含义(架构,静态数据结构,动态工作单元)
Fiber的结构和内容 (function FiberNode(){.....}) 以及详细的介绍和说明;
双缓存结构
利用这种数据数据结构 我们可以高效的更新DOM;在内存中构建并直接替换的技术叫做双缓存;在React中的双缓存Tree
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;React 通过根节(rootFiberNode)点的Current指针指向不同的 FiberTree上的 rootFiber 来完成Tree的切换; mount时 和Update的时候的切换过程是怎么样的?;在更新Tree的过程中 我们有一个算法 会决定是否复用 没有变化的FiberNode ,这个算法就是 React的Diff算法;
流程梳理
FiberNode 和 FiberTree 和是如何创建的?它们都是在 Render阶段的performSyncWorkOnRoot(同步) 和performConcurrentWorkOnRoot(异步 方法 中创建的并完成连接的,比如;具体的流程是:
下面是一个简单的例子 fiber结构如下:
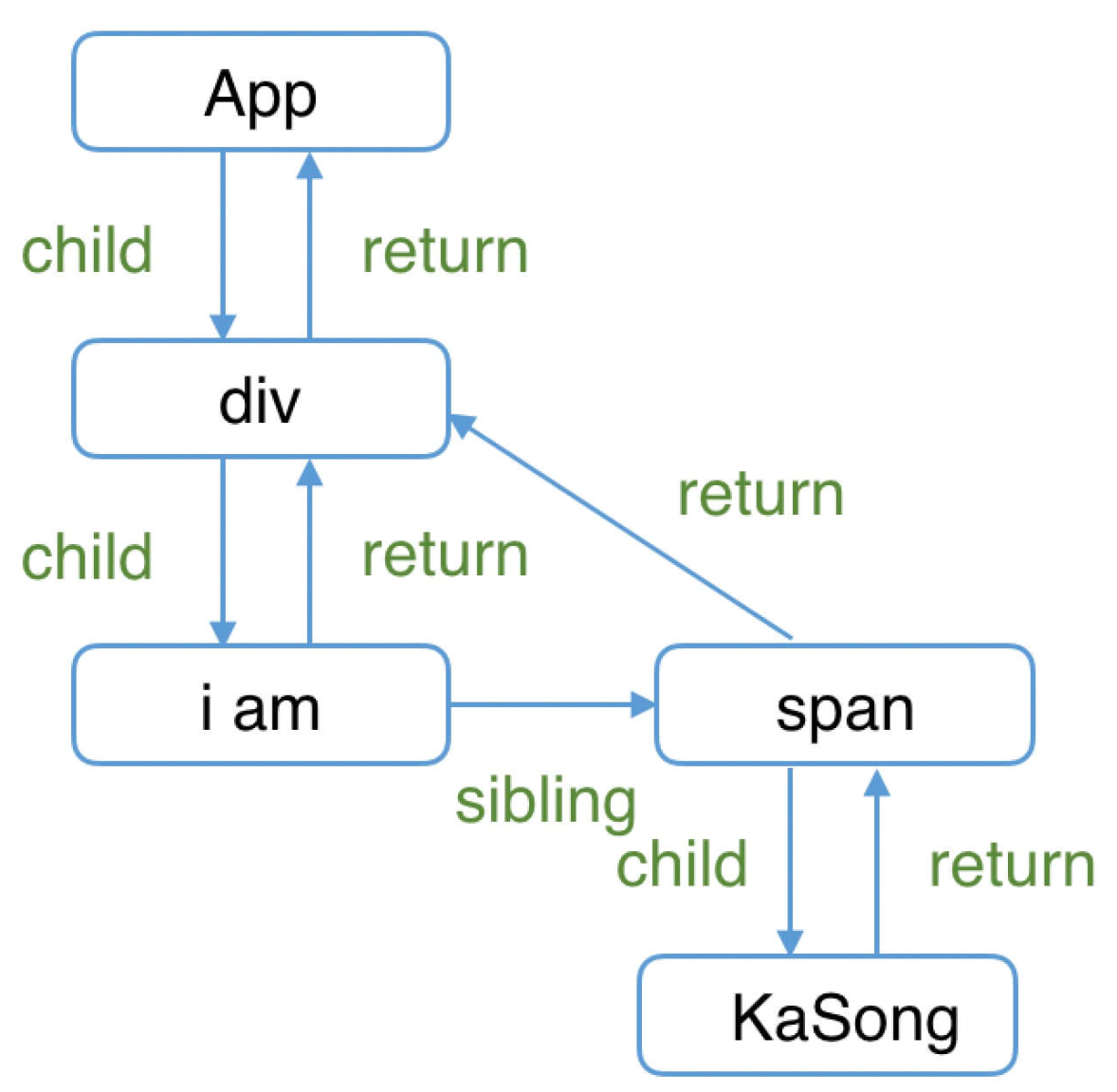
render 的执行过程 (重点Span标签由于React内部优化的原因,不会处理它的子节点的 (归阶段completeWork),在只有一个文本节点的时候 不会生产fiber 不走comleteWork)
1. rootFiber beginWork
2. App Fiber beginWork
3. div Fiber beginWork
4. "i am" Fiber beginWork
5. "i am" Fiber completeWork
6. span Fiber beginWork
7. span Fiber completeWork
8. div Fiber completeWork
9. App Fiber completeWork
10. rootFiber completeWork两个Work
这里的两个Work就是指 前面的提到的 beginWork 和 completeWork;
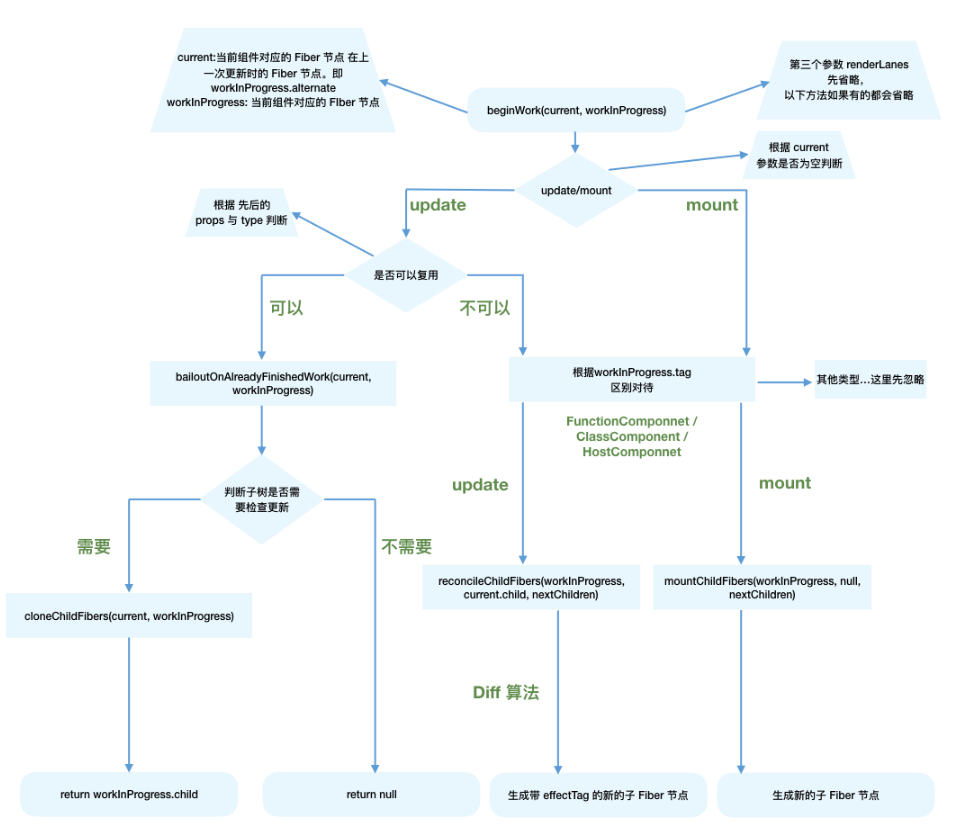
beginWork
三个参数的含义;两个场景的流程mount和update时;
mount时 每次beginWork的结束完之后会创建一个FiberNode
function beginWork(
// 上次的 fiber
current: Fiber | null,
// 当前组件对应的Fiber节点
workInProgress: Fiber,
// 调度优先级 先不管
renderLanes: Lanes,
): Fiber | null {
// 由于首评渲染 没有 current 所以 current === null ?来区分组件是处于mount还是update。
// update时:如果current存在可能存在优化路径,可以复用current(即上一次更新的Fiber节点)
if (current !== null) {
// ...省略
// 复用current
return bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes,
);
} else {
didReceiveUpdate = false;
}
// mount时:根据tag不同,创建不同的子Fiber节点
switch (workInProgress.tag) {
case IndeterminateComponent:
// ...省略
case LazyComponent:
// ...省略
case FunctionComponent:
// ...省略
case ClassComponent:
// ...省略
case HostRoot: // // 根组件就是这个
// ...省略
case HostComponent:
// ...省略
case HostText:
// ...省略
// ...省略其他类型
// 最终我们会进入 reconcileChildren function
}
}reconcileChilder做了些什么? 做两个事情
- 对于mount的组件,他会创建新的子Fiber节点
- uopdate的时候 执行diff算法 对比fiber 查看复用
export function reconcileChildren(
current: Fiber | null,
workInProgress: Fiber,
nextChildren: any,
renderLanes: Lanes
) {
if (current === null) {
// 对于mount的组件
workInProgress.child = mountChildFibers(
workInProgress,
null,
nextChildren,
renderLanes,
);
} else {
// 对于update的组件
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child,
nextChildren,
renderLanes,
);
}
}render阶段的工作是在内存中进行,当工作结束后会通知Renderer需要执行的DOM操作。要执行DOM操作的具体类型就保存在fiber.effectTag中。
effectTag 表示要执行的DOM操作;
// DOM需要插入到页面中
export const Placement = /* */ 0b00000000000010;
// DOM需要更新
export const Update = /* */ 0b00000000000100;
// DOM需要插入到页面中并更新
export const PlacementAndUpdate = /* */ 0b00000000000110;
// DOM需要删除
export const Deletion = /* */ 0b00000000001000;
// 更多类型关于effectTag 表示要指向插入操作 需要满足的条件:
- fiber.stateNode 表示 fiber中保存了DOM
- fiber.effectTag &= Placment != 0,表示 fiber节点存在Placment EffectTag
mount时虽然 stateNode = null ,但是会在completetWork中处理完成,对于mount时 只会给rootFiberNode 打算 Placemnet EffectTag其子fiber 不需要做插入操作。
mont时总结:
当某一个fibr进入beginWork时要走下面的路程:最终的目的 就是创建当前fiber节点的第一个子fiber节点,
- 先判断fiber不同的类型 进行不同的update逻辑
- 判断workInperr看看是否需要标记effctTag
- 进入recondile逻辑,看看当前fiber的chiler是什么类型,具体执行什么操作
- 最终创建 一个Fiber返回
update时的执行过程:
// didReceiveUpdate === false(即可以直接复用前一次更新的子Fiber,不需要新建子Fiber)
if (current !== null) {
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (
oldProps !== newProps ||
hasLegacyContextChanged() ||
(__DEV__ ? workInProgress.type !== current.type : false)
) {
// oldProps === newProps && workInProgress.type === current.type,
// 即props与fiber.type不变
didReceiveUpdate = true;
} else if (!includesSomeLane(renderLanes, updateLanes)) {
// !includesSomeLane(renderLanes, updateLanes),
// 即当前Fiber节点优先级不够,会在讲解Scheduler时介绍
didReceiveUpdate = false;
switch (workInProgress.tag) {
// 省略处理
}
return bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes,
);
} else {
didReceiveUpdate = false;
}
} else {
didReceiveUpdate = false;
}对于FunctionCompommet 来说 会在内部执行一次 这个Function ,然后返回这个jsx对象。内部调用链路是 renderWithHooks 的返回值 作为 nexChildren 然后继续向下传递 进入reconcileChildren
CompletWork
和beginwork类似,对不同的fiber.tag 做不同的处理;
重点关注一下渲染必选的hostComponent( 原生DOM组件对应的Fiber Node )这种fiber.tag;
也是分两个阶段 update时 和 mount时;
当update时,Fiber节点已经存在对应DOM节点,所以不需要生成DOM节点。需要做的主要是处理props
从代码来看 udate我那之后的最后调用栈会 被处理完的props会被赋值给workInProgress.updateQueue 然后在后续的commi阶段使用到它
if (current !== null && workInProgress.stateNode != null) {
// update的情况
updateHostComponent(
current,
workInProgress,
type,
newProps,
rootContainerInstance,
);
}mount 时 主要做三个事情
- 为FiberNode 生成对于的DOM
- 把子孙的DOM插入到 生成的DOM中去
- 处理Porps (同update时的过程)
前文提到 "对于mount时 只会给rootFiberNode 打 Placemnet EffectTag其子fiber 不需要做插入操作。" 其rootFiberNode 的子 fiber对于的DOM如何追加的呢?秘密就在componnetWork这里。它会调用一个appendAllChildren,把子的fiberNode以及其DOM 追加到rootFiberNode上去(这一步完成之 在内存中就会存在一颗完整的dom tree了),形成一颗内存中的Tree(包括DOM和Fiber)然后他会在Commit 阶段渲染到页面去;
关于effectList, 前文提到 effect保存了 fiberNode上的将要执行的何种DOM操作,如果每次遍历这颗大的FiberNodeTree性能是不好的,在React中 我们会把所有涉及到的effect保存成一条单向链表,遍历它以完成各种effect操作
rootFiber.firstEffect -----------> fiber -----------> fiber走完上面的流程 ,信息齐全的双缓存FiberTree就准备好了,接下里就是交给 commit去渲染了
commitRoot(root)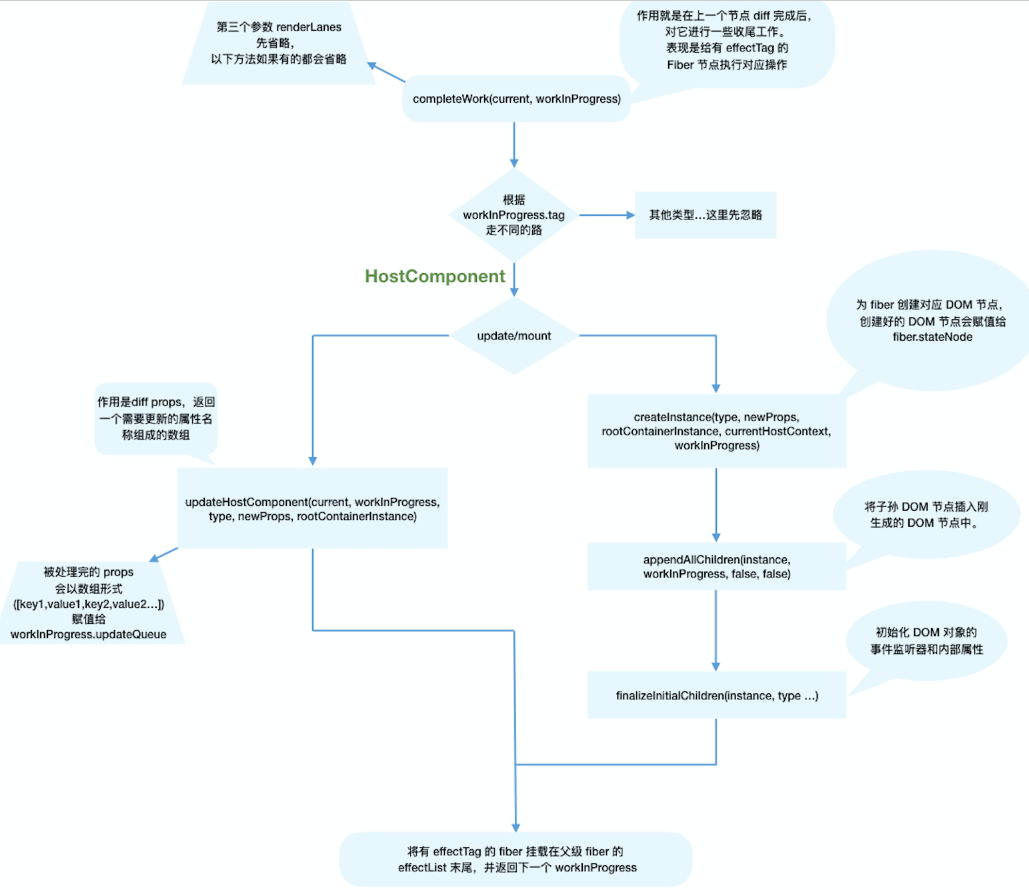
Commit阶段
生命周期啊 hooks effect啊 props 的变化 ,都在这个阶段处理
commit阶段的处理分三个部分(mutation 的前中后)
before mutaion dom操作前;mutation dom操作中;layout dom 操作后;
commitRoot方法是comit阶段的入口,传递的参数是fiberRootNode,它上面会保存一条需要执行的副作用 fiber节点构建的当向链表effectList,这些fiber上的updateQueue中保存了 变化的porps
我们来看一下代码
before mutaion 前
do {
// 触发useEffect回调与其他同步任务。由于这些任务可能触发新的渲染,所以这里要一直遍历执行直到没有任务
flushPassiveEffects();
} while (rootWithPendingPassiveEffects !== null);
// root指 fiberRootNode
// root.finishedWork指当前应用的rootFiber
const finishedWork = root.finishedWork;
// 凡是变量名带lane的都是优先级相关
const lanes = root.finishedLanes;
if (finishedWork === null) {
return null;
}
root.finishedWork = null;
root.finishedLanes = NoLanes;
// 重置Scheduler绑定的回调函数
root.callbackNode = null;
root.callbackId = NoLanes;
let remainingLanes = mergeLanes(finishedWork.lanes, finishedWork.childLanes);
// 重置优先级相关变量
markRootFinished(root, remainingLanes);
// 清除已完成的discrete updates,例如:用户鼠标点击触发的更新。
if (rootsWithPendingDiscreteUpdates !== null) {
if (
!hasDiscreteLanes(remainingLanes) &&
rootsWithPendingDiscreteUpdates.has(root)
) {
rootsWithPendingDiscreteUpdates.delete(root);
}
}
// 重置全局变量
if (root === workInProgressRoot) {
workInProgressRoot = null;
workInProgress = null;
workInProgressRootRenderLanes = NoLanes;
} else {
}
// 将effectList赋值给firstEffect
// 由于每个fiber的effectList只包含他的子孙节点
// 所以根节点如果有effectTag则不会被包含进来
// 所以这里将有effectTag的根节点插入到effectList尾部
// 这样才能保证有effect的fiber都在effectList中
let firstEffect;
if (finishedWork.effectTag > PerformedWork) {
if (finishedWork.lastEffect !== null) {
finishedWork.lastEffect.nextEffect = finishedWork;
firstEffect = finishedWork.firstEffect;
} else {
firstEffect = finishedWork;
}
} else {
// 根节点没有effectTag
firstEffect = finishedWork.firstEffect;
}`mutaion 后
const rootDidHavePassiveEffects = rootDoesHavePassiveEffects;
// useEffect相关
if (rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = false;
rootWithPendingPassiveEffects = root;
pendingPassiveEffectsLanes = lanes;
pendingPassiveEffectsRenderPriority = renderPriorityLevel;
} else {}
// 性能优化相关
if (remainingLanes !== NoLanes) {
if (enableSchedulerTracing) {
// ...
}
} else {
// ...
}
// 性能优化相关
if (enableSchedulerTracing) {
if (!rootDidHavePassiveEffects) {
// ...
}
}
// ...检测无限循环的同步任务
if (remainingLanes === SyncLane) {
// ...
}
// 在离开commitRoot函数前调用,触发一次新的调度,确保任何附加的任务被调度
ensureRootIsScheduled(root, now());
// ...处理未捕获错误及老版本遗留的边界问题
// 执行同步任务,这样同步任务不需要等到下次事件循环再执行
// 比如在 componentDidMount 中执行 setState 创建的更新会在这里被同步执行
// 或useLayoutEffect
flushSyncCallbackQueue();
return null;before mutation
整个过程就是遍历effectList 并执行 commitBeforeMutationEffects ,传递的是 finishWork(),commitBeforeMuationEffects 源码如下
function commitBeforeMutationEffects() {
while (nextEffect !== null) {
const current = nextEffect.alternate;
if (!shouldFireAfterActiveInstanceBlur && focusedInstanceHandle !== null) {
// ...focus blur相关
}
const effectTag = nextEffect.effectTag;
// 调用getSnapshotBeforeUpdate
if ((effectTag & Snapshot) !== NoEffect) {
commitBeforeMutationEffectOnFiber(current, nextEffect);
}
// 调度useEffect
if ((effectTag & Passive) !== NoEffect) {
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects();
return null;
});
}
}
nextEffect = nextEffect.nextEffect;
}
}观察到它做了下面几件事:
- 处理DOM 渲染前后的autoFocus,blur逻辑
- 调用getSnapshotBeforeUpdate
- 调度useEffect
调用生命周期getSnapshotBeforeUpdate(这个函数是为了应对15 -> Fiber 的升级过程中,由于 fiber为可中断的更新,为避免多次调用componentWillXXX,而设计的一个 生命周期function)。注意comit阶段是同步的,这个生命周期不会遇到多次调度的问题。这个生命周期的调用的入口在 commitBeforeMutationEffectOnFiber 中,它会取到当前ClassCompomet的instan 上然后判断是否含有 这个生命周期,如果有就会调用
function commitBeforeMutationLifeCycles(
current: Fiber | null,
finishedWork: Fiber,
): void {
switch (finishedWork.tag) {
case FunctionComponent:
case ForwardRef:
case SimpleMemoComponent:
case Block: {
return;
}
case ClassComponent: {
// ++++++
if (finishedWork.effectTag & Snapshot) {
const snapshot = instance.getSnapshotBeforeUpdate(
finishedWork.elementType === finishedWork.type
? prevProps
: resolveDefaultProps(finishedWork.type, prevProps),
prevState,
);
// +++++
}useEffect 的调度或许有点难以理解,这是一个异步的调度过程,触发的是useEffect的flushPassiveEffects function,
// 存在useEffect,调度他
if ((effectTag & Passive) !== NoEffect) {
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
// 调度器 scheduleCallback是 另一个模块的事情
scheduleCallback(NormalSchedulerPriority, () => {
// 触发useEffect
flushPassiveEffects();
return null;
});
}
}flushPassiveEffects 具体的操作是什么?
它从全局变量 rootWithPendingPassiveEffects 获取effectList (这里面包括所有了副作用操作包括useEffect..., 总而言之 effectTag的类型有很多哈)然后遍历这个list 并且执行effect的回调,rootWithPendingPassiveEffects 的具体赋值操作在Layotu中进行。
const rootDidHavePassiveEffects = rootDoesHavePassiveEffects;
// 这个条件 决定了 是否给 rootWithPendingPassiveEffects 赋值
if (rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = false;
rootWithPendingPassiveEffects = root;
pendingPassiveEffectsLanes = lanes;
pendingPassiveEffectsRenderPriority = renderPriorityLevel;
}故而 总体流程是:
- before mutation阶段在scheduleCallback中调度flushPassiveEffects
- layout阶段之后将effectList赋值给rootWithPendingPassiveEffects
- scheduleCallback触发flushPassiveEffects,flushPassiveEffects内部遍历rootWithPendingPassiveEffects
异步的调用 使得它适用于许多常见的副作用场景
题外话:推荐一个vsCode插件bookmark,他可以让你在代码的某处打一个标签🏷️,对阅读源代大量代码有帮助
mutation
这个阶段也是 遍历 effectList, 具体的执行在 commitMutaionEffects中。对每个fiberNode执行下面的操作
function commitMutationEffects(root: FiberRoot, renderPriorityLevel) {
// 遍历effectList
while (nextEffect !== null) {
const effectTag = nextEffect.effectTag;
// 根据 ContentReset effectTag重置文字节点
if (effectTag & ContentReset) {
commitResetTextContent(nextEffect);
}
// 更新ref
if (effectTag & Ref) {
const current = nextEffect.alternate;
if (current !== null) {
commitDetachRef(current);
}
}
// 根据 effectTag 分别处理
const primaryEffectTag =
effectTag & (Placement | Update | Deletion | Hydrating);
switch (primaryEffectTag) {
// 插入DOM
case Placement: {
commitPlacement(nextEffect);
nextEffect.effectTag &= ~Placement;
break;
}
// 插入DOM 并 更新DOM
case PlacementAndUpdate: {
// 插入
commitPlacement(nextEffect);
nextEffect.effectTag &= ~Placement;
// 更新
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
// SSR
case Hydrating: {
nextEffect.effectTag &= ~Hydrating;
break;
}
// SSR
case HydratingAndUpdate: {
nextEffect.effectTag &= ~Hydrating;
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
// 更新DOM
case Update: {
const current = nextEffect.alternate;
commitWork(current, nextEffect);
break;
}
// 删除DOM
case Deletion: {
commitDeletion(root, nextEffect, renderPriorityLevel);
break;
}
}
nextEffect = nextEffect.nextEffect;
}
}
- 重置文本节点
- 更新ref
- 分别处理不同的effectTag (重点关注 Placment Tag,update Tag,deletion Tag)
分别看看同步的effectTag 具体干了些啥,
Placement tag , commitPlacement 是处理 DOM插入的,这需要获取它是所有的 父亲兄弟DOM,然后执行insertBefore 或者 appendChild,(注意DOM的节点层级和fiber的层级 并不是一一对应的哈)
// 1.获取父亲DOM
const parentFiber = getHostParentFiber(finishedWork);
// 父级DOM节点
const parentStateNode = parentFiber.stateNode;
// 2.获取fibe的兄弟dom
const before = getHostSibling(finishedWork);
// 3. 看看是否决定插入操作
// parentStateNode是否是rootFiber
if (isContainer) {
insertOrAppendPlacementNodeIntoContainer(finishedWork, before, parent);
} else {
insertOrAppendPlacementNode(finishedWork, before, parent);
}如果遇到 update effectTag 这意味,这个Fiber 需要更新 ,主要关注 两个不同场景的处理FunctionComponent和HostComponen,
FunctionComponent 调用commitHookEffectListUnmount,遍历effectList 执行 useLayoutEffect的销毁函数(就是runter那个 function)操作。
hostComponent 会调用commitUpdate,吧compoWork中fiberNode 赋值updateQueue的内容渲染到页面上
for (let i = 0; i < updatePayload.length; i += 2) {
const propKey = updatePayload[i];
const propValue = updatePayload[i + 1];
// 处理 style
if (propKey === STYLE) {
setValueForStyles(domElement, propValue);
// 处理 DANGEROUSLY_SET_INNER_HTML
} else if (propKey === DANGEROUSLY_SET_INNER_HTML) {
setInnerHTML(domElement, propValue);
// 处理 children
} else if (propKey === CHILDREN) {
setTextContent(domElement, propValue);
} else {
// 处理剩余 props
setValueForProperty(domElement, propKey, propValue, isCustomComponentTag);
}
}Deletion effectTag 意味着删除内容。将调用 commitDeletion,主要做下面的事情,
源代码请访问 commitDeletion源代码
- 递归处理所有的fiber对应的componentWillUnmount,移除DOM
- 解除ref
- 调用所有的 useEffect的销毁function
Layout
这个阶段是所有DOM 修改完之后的执行的由于JS的堵塞 所有浏览器还没有完成渲染哈!。同样的也是遍历 effectList 调用的是commitLayoutEffects。
commitLayoutEffect 主要的工作是
- commitLayoutEffectOnFiber 生命周期钩子调用 + hooks
- 赋值ref commitAttachRef
具体来说,commitLayoutEffectOnFiber(commitLifeCycles) 做了下面的事情
- 对于ClassComponent 依据current 是否有值,看看是mount /update,分别调用 DitMout/DitUpdate。若是FunctionCompnent中是setState有回调的画,也会在此调用
- 对于FunctionComponent 会调用 useLayoutEffect(你可以发现 它的上次更新的调回 和本次更新的回调是同步进行的) 而useEffect 需要先在schedule中调度,然后再commit中进行 回调 这是异步的。
- 对于HostRoot 它会在这个阶段执行 第三个cb 回调
ReactDOM.render(<App />, document.querySelector("#root"),
function() { // 第三个参数 回调
console.log("i am mount~");
});对于 commitAttachRef 就简单许多了。做两件事:获取DOM实例,更新Ref
至此 layout阶段就结束了。
在Mutation 阶段结束后 Layout开始前执行。 root.current = finshiWork 完成双缓存数的切换(这行代码的作用就是切换rootFiberNode指向的current Fiber树。) 因为componentWillUnmount 会在mutation 阶段执行,此时 fiber tree还没有切,到了Layout 会执行 DidMount / DitUpdate 这个时候需要获取最新的fiber tree,所以切换的操做是夹在两个阶段之间完成的。
对比两个useEffect & useLayoutEffect

Diff算法
这里的diff算法是指在 前面提到的beginWork中的update时的 fiber节点对比复用的具体实现。

大量的Tree节点的对比和diff往往性能很烂,因此 react优化了这类的算法
- 只对同级元素进行diff 如果跨层级了就不打算 复用
- 如果两次对比中 发现是不一样的 元素类型 直接不复用
- 开发者 可以通过key 来指定 要不要复用
算法是入口是在 reconcileChildFibers 这个function 中,它依据传入的newChild(JSX对象) 类型来做不同的处理,若为object number string 那么就是表示同级只要一个节点,如果是Array说明是包含 同层级包含多个节点,
于是我们就有两种不同的处理场景
// 根据newChild类型选择不同diff函数处理
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
): Fiber | null {
const isObject = typeof newChild === 'object' && newChild !== null;
if (isObject) {
// object类型,可能是 REACT_ELEMENT_TYPE 或 REACT_PORTAL_TYPE
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
// 调用 reconcileSingleElement 处理
// // ...省略其他case
}
}
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 调用 reconcileSingleTextNode 处理
// ...省略
}
if (isArray(newChild)) {
// 调用 reconcileChildrenArray 处理
// ...省略
}
// 一些其他情况调用处理函数
// ...省略
// 以上都没有命中,删除节点
return deleteRemainingChildren(returnFiber, currentFirstChild);
}单节点Diff
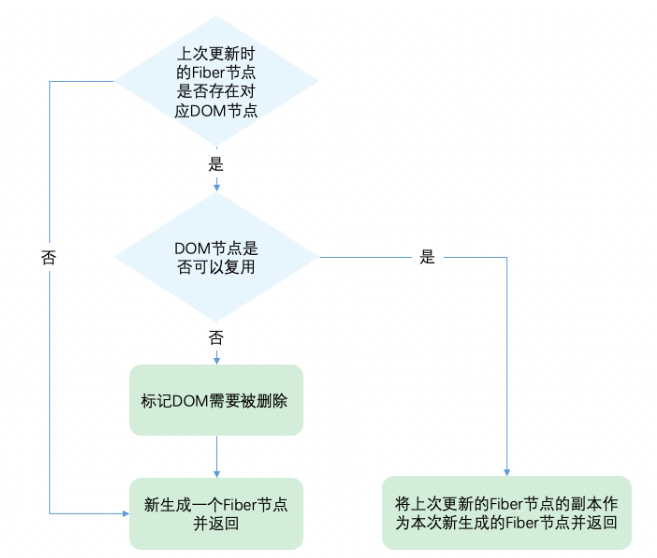
关于是否复用的逻辑在 reconcileSingleElement function中
- 当child !== null且key相同且type不同时执行deleteRemainingChildren将child及其兄弟fiber都标记删除。
- 当child !== null且key不同时仅将child标记删除。
其源代码长这样
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
// 首先比较key是否相同
if (child.key === key) {
// key相同,接下来比较type是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// type相同则表示可以复用
// 返回复用的fiber
return existing;
}
// type不同则跳出switch
break;
}
}
// 代码执行到这里代表:key相同但是type不同
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
// key不同,将该fiber标记为删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回 ...省略
}下面是一个简单的例子
// 当前页面显示的
ul > li * 3
// 这次需要更新的
ul > p
// 由于本次更新只有一个p节点,所以是属于“同级只有一层”会走 单diff更新。
// reconcileSingleElement 会遍历之前的3个li ,寻找本次更新的p是否与之可以复用,
// 这里就要分两种情况了
1.Key同 Type不同
他会这样走逻辑:key同表示我们找到了上次与p相同的fiber ,但是type(p/li)不同。那么上次的li
都会被删除
2. Key 不同 上次的fiber不能被p复用,直接删除与之相关的所有子节点多节点Diff
有些许的复杂,但是不难。
这样的jsx 就代表为多节点
function List () {
return (
<ul>
<li key="0">0</li>
<li key="1">1</li>
<li key="2">2</li>
<li key="3">3</li>
</ul>
)
}
// ===>
{
$$typeof: Symbol(react.element),
key: null,
props: {
children: [
{$$typeof: Symbol(react.element), type: "li", key: "0", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "1", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "2", ref: null, props: {…}, …}
{$$typeof: Symbol(react.element), type: "li", key: "3", ref: null, props: {…}, …}
]
},
ref: null,
type: "ul"
}他会进入reconcileChildrenArray 中开始做diff
主要分了三种情况:节点更新比如属性变化,类型变化;节点新增或创建;节点位置变化。
由于不能使用双指针进行优化,我们需要进行两次遍历
- 第一轮 遍历更新的节点
- 第二轮 遍历不需要 更新 的节点
具体的情况说明是如何进行的
重点关注 节点位置 移动的 fiber更新是如何进行diff的,以及他们的Demo样式
下面是另一个全流程的DEMO
// 之前
abcd
// 之后
acdb
===第一轮遍历开始===
a(之后)vs a(之前)
key不变,可复用
此时 a 对应的oldFiber(之前的a)在之前的数组(abcd)中索引为0
所以 lastPlacedIndex = 0;
继续第一轮遍历...
c(之后)vs b(之前)
key改变,不能复用,跳出第一轮遍历
此时 lastPlacedIndex === 0;
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === cdb,没用完,不需要执行删除旧节点
oldFiber === bcd,没用完,不需要执行插入新节点
将剩余oldFiber(bcd)保存为map
// 当前oldFiber:bcd
// 当前newChildren:cdb
继续遍历剩余newChildren
key === c 在 oldFiber中存在
const oldIndex = c(之前).index;
此时 oldIndex === 2; // 之前节点为 abcd,所以c.index === 2
比较 oldIndex 与 lastPlacedIndex;
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动
并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
在例子中,oldIndex 2 > lastPlacedIndex 0,
则 lastPlacedIndex = 2;
c节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:bd
// 当前newChildren:db
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
oldIndex 3 > lastPlacedIndex 2 // 之前节点为 abcd,所以d.index === 3
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:b
// 当前newChildren:b
key === b 在 oldFiber中存在
const oldIndex = b(之前).index;
oldIndex 1 < lastPlacedIndex 3 // 之前节点为 abcd,所以b.index === 1
则 b节点需要向右移动
===第二轮遍历结束===
最终acd 3个节点都没有移动,b节点被标记为移动
// 之前
abcd
// 之后
dabc
===第一轮遍历开始===
d(之后)vs a(之前)
key改变,不能复用,跳出遍历
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === dabc,没用完,不需要执行删除旧节点
oldFiber === abcd,没用完,不需要执行插入新节点
将剩余oldFiber(abcd)保存为map
继续遍历剩余newChildren
// 当前oldFiber:abcd
// 当前newChildren dabc
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
此时 oldIndex === 3; // 之前节点为 abcd,所以d.index === 3
比较 oldIndex 与 lastPlacedIndex;
oldIndex 3 > lastPlacedIndex 0
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:abc
// 当前newChildren abc
key === a 在 oldFiber中存在
const oldIndex = a(之前).index; // 之前节点为 abcd,所以a.index === 0
此时 oldIndex === 0;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 0 < lastPlacedIndex 3
则 a节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:bc
// 当前newChildren bc
key === b 在 oldFiber中存在
const oldIndex = b(之前).index; // 之前节点为 abcd,所以b.index === 1
此时 oldIndex === 1;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 1 < lastPlacedIndex 3
则 b节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:c
// 当前newChildren c
key === c 在 oldFiber中存在
const oldIndex = c(之前).index; // 之前节点为 abcd,所以c.index === 2
此时 oldIndex === 2;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 2 < lastPlacedIndex 3
则 c节点需要向右移动
===第二轮遍历结束===状态更新
概述
我们先复习一下前面提到几个关键节点:
Render阶段的开始于 performSyncWorkOnRoot/performConcurrentWorkOnRoot 的调用(同步/异步更新)
Render完走到 Commit阶段 commitRoot rootFiber作为参数
执行下面的方法可触发Update,
- ReactDOM.render
- this.setState
- this.forceUpdate
- useState
- useReducer
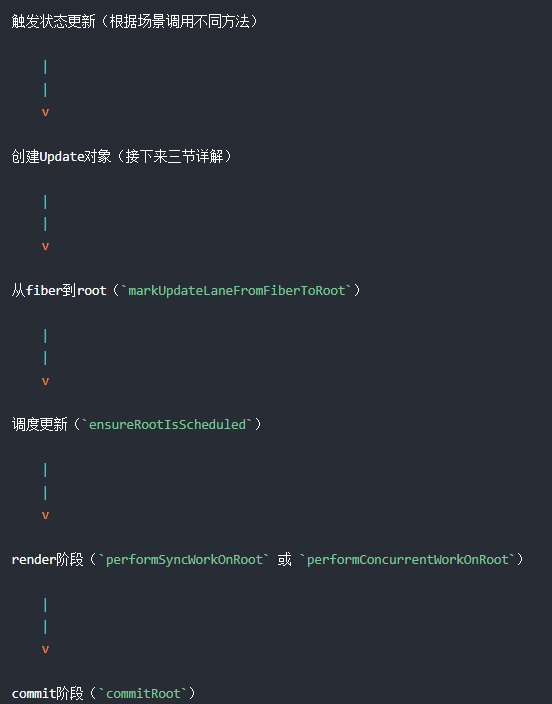
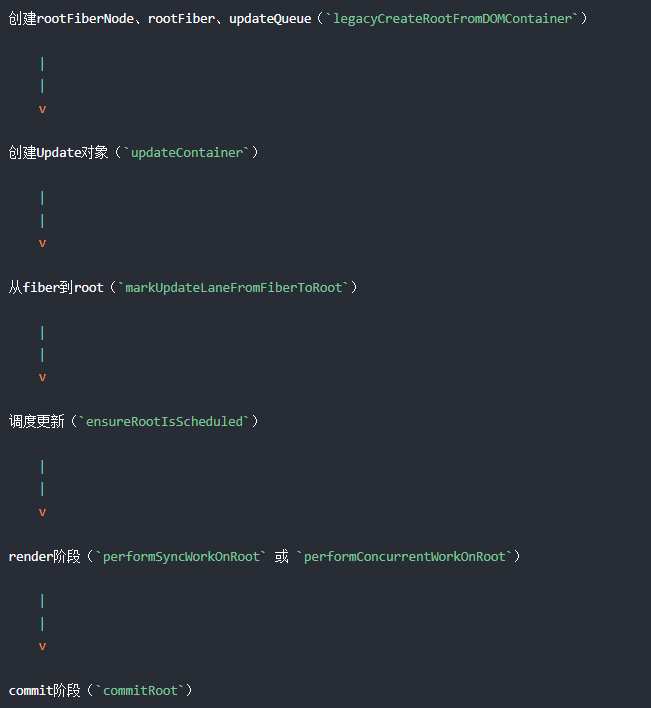
虽然场景不同,每次状态更新都会创建一个保存更新状态相关内容的对象,我们叫他Update。在render阶段的 beginWork 中会根据 Update计算新的state。
现在 “触发状态更新的fiber”上已经存在update对象了,我们要往上找到它的rootFiber 因为render节点是从 rootFiber开始往下遍历的,这个时候调用 markUpdateLaneFromFiberToRoot 就能找到rootFiber,
找到rootFiber之后 进入schedule 依据优先级 进行更新,调用的是“ensureRootIsScheduled”,它的核心就是
if (newCallbackPriority === SyncLanePriority) {
// 任务已经过期,需要同步执行render阶段
newCallbackNode = scheduleSyncCallback(
performSyncWorkOnRoot.bind(null, root)
);
} else {
// 根据任务优先级异步执行render阶段
var schedulerPriorityLevel = lanePriorityToSchedulerPriority(
newCallbackPriority
);
newCallbackNode = scheduleCallback(
schedulerPriorityLevel,
performConcurrentWorkOnRoot.bind(null, root)
);
}依据异步/同步(异步就是18的concureent模式) 分别调用 两个方法,
这个调度更新 enusreRootIsSchedule 中会运用到优先级的概念,在react源码中 又下面的优先级
export type PriorityLevel = 0 | 1 | 2 | 3 | 4 | 5;
// TODO: Use symbols?
export const NoPriority = 0;
export const ImmediatePriority = 1;
export const UserBlockingPriority = 2;
export const NormalPriority = 3;
export const LowPriority = 4;
export const IdlePriority = 5;注意:事件的优先级是 UserBlockingPriority 要高于 setState优先级NormalPriority
优先级和update
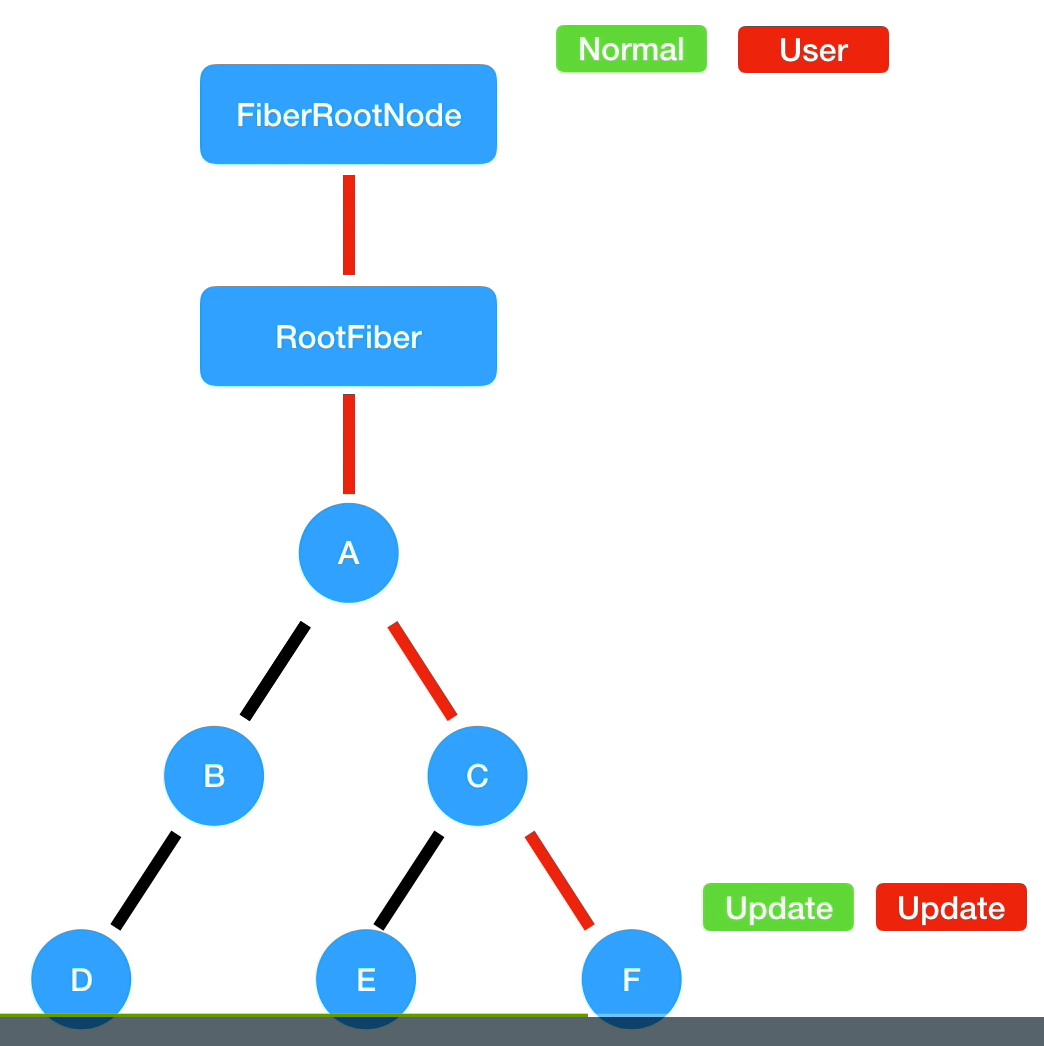
新的state 是基于 优先级update 计算出来的。上述的图描述了这样的场景:
F组件先发生了一次normal的优先级调度,然后从当前fiber开始找到rootFiber 然后以normal的优先级执行深度优先的diff。这个过程还没有结束然后又触发了一个 UserBlockingPriority的高优先级,然后又会开始深度优先遍历,原来的normal优先级会被打断。
观察下面的例子
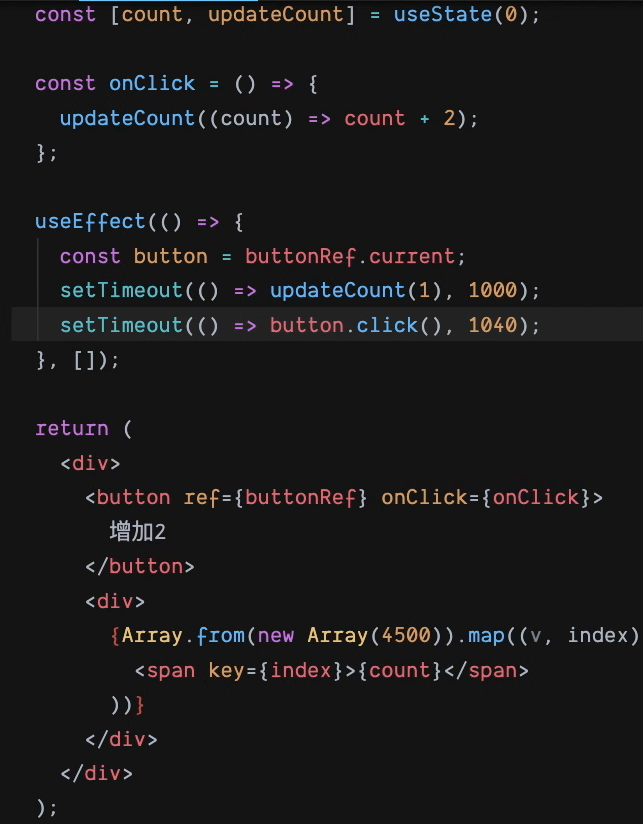
你会发现 r16 的 表现会是这样
:0-1-3
r18 有并发优先级概念,所以你看到这样
:0-2-3
心智模型
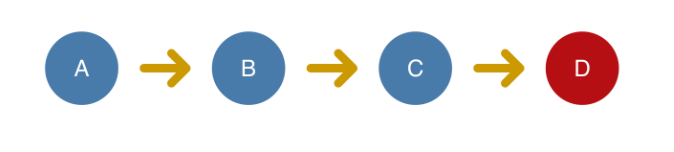
主要分两种 “同步更新的React” “异步更新的React”,
同步更新 类似代码提交,先把前面开发中的功能完成了之后才修复D Bug
在React中,所有通过ReactDOM.render创建的应用(其他创建应用的方式参考ReactDOM.render一节)都是通过类似的方式更新状态。
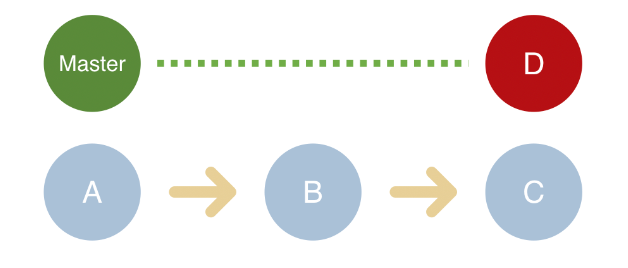
异步更新 类似代码提交 ,先把主干上的D bug修复,然后通过git rebase ,把其他的 ABC 功能 merge 一次没有bug的 master
ReactDOM.createBlockingRoot和ReactDOM.createRoot创建的应用会采用并发的方式更新状态。
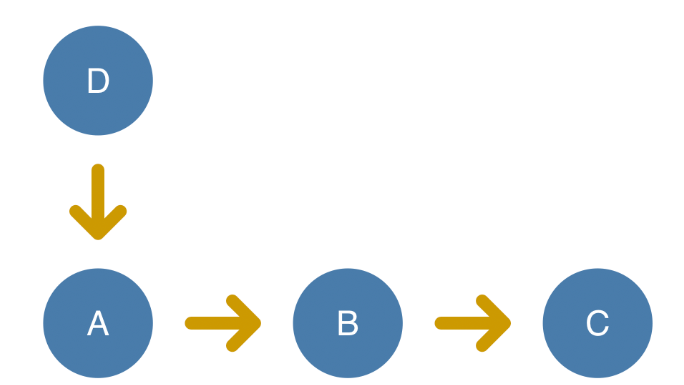
Update
一共三种组件(HostRoot | ClassComponent | FunctionComponent)可以触发更新。
HostRoot | ClassComponent 共用一套更新机制
FunctionComponent 独立用一套更新机制
我们先讲 第一套更新机制
Update的结构
const update: Update<*> = {
eventTime, // 不需要关注
lane, // 不需要关注 与update优先级相关
suspenseConfig, // 不需要关注 与 suspense 相关
tag: UpdateState,
// 更新的类型 UpdateState | ReplaceState | ForceUpdate | CaptureUpdate。
payload: null,
// 更新传递过来的数据,ClassComponent 就是setState第一个参数,HostComponet
// 就是传入的<APP />
callback: null,
// 在 commit 阶段的 layout 子阶段一节中提到的回调函数。
next: null,
//与其他Update连接形成链表。
};Update与Fiber的联系是
Fiber 组成 FiberTree ,然后每个Fiber上的Update 会串联在一起构建一个链表 存储到 fiber.updateQueue 中(Fiber节点最多同时存在两个updateQueue)
- current fiber保存的updateQueue即current updateQueue
- workInProgress fiber保存的updateQueue即workInProgress updateQueue
UpdateQueue结构如下
const queue: UpdateQueue<State> = {
baseState: fiber.memoizedState,
// 本次更新前该Fiber节点的state,Update基于该state计算更新后的state。
// 类似我们在心智模型中说的master主干
firstBaseUpdate: null,
lastBaseUpdate: null,
// 本次更新前 该Fiber节点已保存的Update, 一个是链表头 和链表尾巴
// 类似我们在心智模型中说的 执行git rebase基于的commit(节点D)。
shared: {
pending: null,
},
// 触发更新时,产生的Update会保存在shared.pending中形成单向环状链表。
// update的时候会被剪开 连接到 lastBaseUpdate 后
// 类似我们在心智模型中说的 ABC commit
effects: null,
// 保存update.calback !== null的Update
};一个简单的例子说明;
深入理解调度优先级
react通过Scheduler (具体内部调用为 runWithPriority 方法)调度task,那个优先级高 是依据 update.lane 来决定的。
举例说明
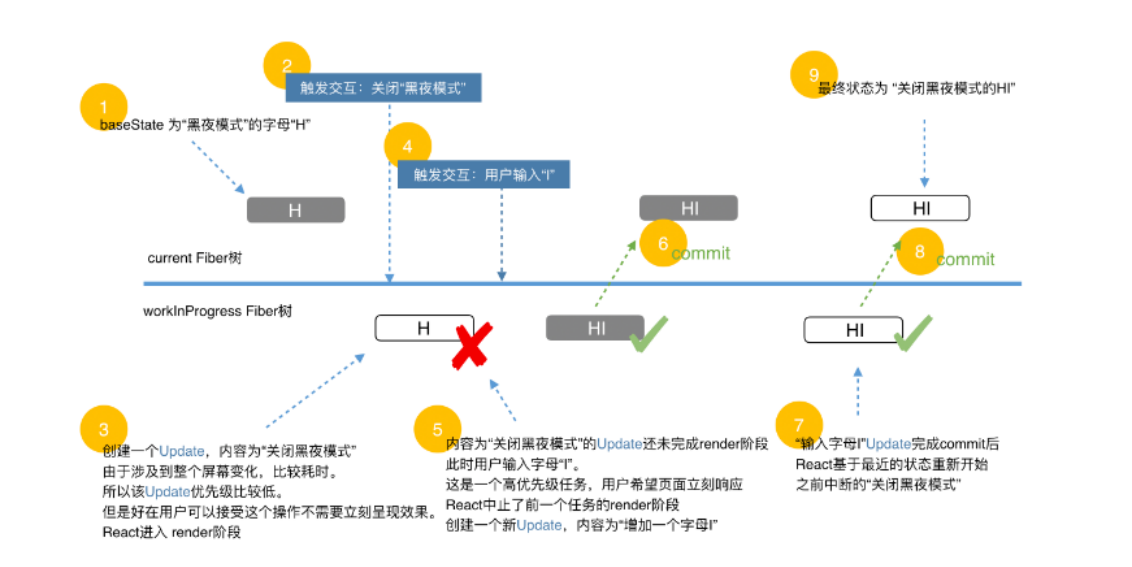
如何保证Update不丢失?
当render阶段被中断后重新开始时,会基于current updateQueue克隆出workInProgress updateQueue。由于current updateQueue.lastBaseUpdate已经保存了上一次的Update,所以不会丢失。
当commit阶段完成渲染,由于workInProgress updateQueue.lastBaseUpdate中保存了上一次的Update,所以 workInProgress Fiber树变成current Fiber树后也不会造成Update丢失。
如何保存 依赖的连续性?
具体来说 会经理多次render 对比下面的例子 (数字代表优先级,值越低优先级越高)
baseState: ''
shared.pending: A1 --> B2 --> C1 --> D2第一次render 高优先级为 A1 - C1 ( 由于B2优先级没C1 高,所以他及其后面的所有Update会被保存在baseUpdate中作为下次更新的Update(即B2 C1 D2)。 )
baseState: ''
baseUpdate: null
render阶段使用的Update: [A1, C1]
memoizedState: 'AC'第二次Render 高优先级为 B2 - C1- D2
baseState: 'A'
baseUpdate: B2 --> C1 --> D2
render阶段使用的Update: [B2, C1, D2]
memoizedState: 'ABCD'ReactDOM.render
我们从头到尾,把前面的流程全部给串联一遍。
React 具备多种入口函数,
- legacy -- ReactDOM.render(
, rootNode) - blocking -- ReactDOM.createBlockingRoot(rootNode).render(
) - concurrent -- ReactDOM.createRoot(rootNode).render(
) (目前React18 就是这种默认模式)任务中断/任务优先级都是针对concurrent模式。
this.setState
其内部会调用 this.updater.enqueueSetState方法,这个方法里面就是熟悉的一套
创建update到调度update的流程了。
然后内部还可以 对this.forceUpdate (强制更新),它会调用到 enqueueForceUpdate 中,它里面进行了一次赋值 update.tag = ForceUpdate,
在ClassComponent 是否更新上 有一个重要的条件 checkHasForceUpdateAfterProcessing,里面就是在判断这个tag
Hook
理念
从设计理念开始叨叨,
React的架构遵循schedule - render - commit的运行流程,这个流程是React世界最底层的运行规律。
如果说 把 react ClassComponent 认为是 react世界的 原子,那么hooks就是react世界的 电子 。
hooks的一个重大设计目的是: 使同一组件在同一时间可以拥有多个状态,即同一个组件可以拥有多条时间线。这是Class无法做到的
使用useDeferredValue使同一组件的某个状态在同一时间拥有多条时间线。
不同时间线重合的时间视用户设备的性能不同而不同。
截止2024/01/07日 ,react官方文档模式已经开始使用使用 react18 并且为 Concurrent Mode 模式而不再是之前的legacy 模式(react 17) ,而Hooks是能够最大限度发挥Concurrent Mode潜力的Component构建方式。
简化版本Hook实现
useState 的工作分两个部分,
- 通过某些途径产生 更新(比如setState(Hook)),更新将导致update
- render 把 useState返回的数据作为结果
更新的本质是一种类似下面的数据结构
const update = {
// 更新执行的函数
action,
// 与同一个Hook的其他更新形成链表
next: null,
};
// 这样的例子中 就会产生三个 update
// 之前
return <p onClick={() => updateNum((num) => num + 1)}>{num}</p>;
// 之后
return (
<p
onClick={() => {
updateNum((num) => num + 1);
updateNum((num) => num + 1);
updateNum((num) => num + 1);
}}
>
{num}
</p>
);
这三个update通过下面的代码进行连接,在一起(环形单向链表)
function dispatchAction(queue, action) {
// 创建update
const update = {
action,
next: null,
};
// 环状单向链表操作
if (queue.pending === null) {
update.next = update;
} else {
update.next = queue.pending.next;
queue.pending.next = update;
}
queue.pending = update;
// 模拟React开始调度更新
schedule();
}调用updateNum 实际上就是调用 dispatchAction
第一个update会产生下面的数据结构
queue.pending = u0 ---> u0
^ |
| |
---------第二个update会产生下面的数据结构
queue.pending = u1 ---> u0
^ |
| |
---------在遍历他们的时候只需要调整指针,指向第一个插入的update就好了。
更新产生的update对象会保存在queue中。对于FunctionCompnent来说它存在fiber上
hook的数据结构:
// App组件对应的fiber对象
const fiber = {
// 保存该FunctionComponent对应的Hooks链表
// fiber.memoizedState中保存的Hook的数据结构。
memoizedState: null,
// 指向App函数
stateNode: App,
};
// hooks 数据结构是这样的
hook = {
// 保存update的queue,即上文介绍的queue
queue: {
pending: null,
},
// 保存hook对应的state
memoizedState: initialState,
// 与下一个Hook连接形成单向无环链表
next: null,
};
update和hook的关系: .
每个useState对应一个hook对象。产生的update保存在useState对应的hook.queue中。
模拟一些Schedule的调度过程,实际上主要还是分两个场景 mount 和update的时候。数据的保存和链表的移动。计算state也是一样的道理。下面是useState的部分源码
function useState(initialState) {
let hook;
// 首次render时是mount
if (isMount) {
// ...mount时需要生成hook对象
hook = {
queue: {
pending: null,
},
memoizedState: initialState,
next: null,
};
if (!fiber.memoizedState) {
// 将hook插入fiber.memoizedState链表末尾
fiber.memoizedState = hook;
} else {
workInProgressHook.next = hook;
}
// 移动workInProgressHook指针
workInProgressHook = hook;
} else {
// ...update时从workInProgressHook中取出该useState对应的hook
// // update时找到对应hook 并且移动指针
hook = workInProgressHook;
workInProgressHook = workInProgressHook.next;
}
// update执行前的初始state
let baseState = hook.memoizedState;
if (hook.queue.pending) {
// ...根据queue.pending中保存的update更新state
// // 获取update环状单向链表中第一个update
let firstUpdate = hook.queue.pending.next;
do {
// 执行update action
const action = firstUpdate.action;
baseState = action(baseState);
firstUpdate = firstUpdate.next;
} while (firstUpdate !== hook.queue.pending.next);
// 清空queue.pending
hook.queue.pending = null;
}
// 将update action执行完后的state作为memoizedState
hook.memoizedState = baseState;
return [baseState, dispatchAction.bind(null, hook.queue)];
}这里是我们自己mock的一个useState 重要!
let workInProgressHook;
let isMount = true;
const fiber = {
memoizedState: null,
stateNode: App
};
function schedule() {
workInProgressHook = fiber.memoizedState;
const app = fiber.stateNode();
isMount = false;
return app;
}
function dispatchAction(queue, action) {
const update = {
action,
next: null
}
if (queue.pending === null) {
update.next = update;
} else {
update.next = queue.pending.next;
queue.pending.next = update;
}
queue.pending = update;
schedule();
}
function useState(initialState) {
let hook;
if (isMount) {
hook = {
queue: {
pending: null
},
memoizedState: initialState,
next: null
}
if (!fiber.memoizedState) {
fiber.memoizedState = hook;
} else {
workInProgressHook.next = hook;
}
workInProgressHook = hook;
} else {
hook = workInProgressHook;
workInProgressHook = workInProgressHook.next;
}
let baseState = hook.memoizedState;
if (hook.queue.pending) {
let firstUpdate = hook.queue.pending.next;
do {
const action = firstUpdate.action;
baseState = action(baseState);
firstUpdate = firstUpdate.next;
} while (firstUpdate !== hook.queue.pending)
hook.queue.pending = null;
}
hook.memoizedState = baseState;
return [baseState, dispatchAction.bind(null, hook.queue)];
}
function App() {
const [num, updateNum] = useState(0);
console.log(`${isMount ? 'mount' : 'update'} num: `, num);
return {
click() {
updateNum(num => num + 1);
}
}
}
window.app = schedule();Hook的数据结构
在正式的React中 我们并不是通过isMount 来区分 mount 和update,在不同阶段React不同的Hook对象,这类对象在源码中被称 dispacter ,他们是分成了两类(mount时和update时), 当然dispatcher 不仅仅只有这两类哈 还有更多的类型。下面是 部分源代码
ReactCurrentDispatcher.current =
current === null || current.memoizedState === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate; hook的数据结构如下:注意区分 fiber的memoizedState 和 hook的memoizedState 不是一个东西哈,前者是fiber上保存的hook链表,后者是hook上保存的单一数据。
const hook: Hook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null,
};
useState和useReducer
本质来说,useState只是预置了reducer的useReducer。下面是一部分有关useState和useReducer的源代码。
function useState(initialState) {
var dispatcher = resolveDispatcher();
return dispatcher.useState(initialState);
}
function useReducer(reducer, initialArg, init) {
var dispatcher = resolveDispatcher();
return dispatcher.useReducer(reducer, initialArg, init);
}这两个hook 的工作流程分成了 声明 和 调用 两个阶段 (声明的时候会调用一次,然后执行更新的时候就会执行一次)
mount 时:
声明是在 FunctionComponent 进入render阶段的beginwork 调用 renderWithHooks 发生的。
这个function 会按照 mount /update 场景分别进行处理。
mount时,useReducer会调用mountReducer,useState会调用mountState。
对于上面的两个hook实际上都会创建 queue,queue的数据结构是:
const queue = (hook.queue = {
// 与极简实现中的同名字段意义相同,保存update对象
pending: null,
// 保存dispatchAction.bind()的值
dispatch: null,
// 上一次render时使用的reducer
lastRenderedReducer: reducer,
// 上一次render时的state
lastRenderedState: (initialState: any),
});不同的是 他们的 lastRenderedReducer 参数不一样。
useState 是有一个默认的 basicStateReducer,useReducer 是传入的 reducer,但.... basicStateReducer 好像挺简单的
function basicStateReducer<S>(state: S, action: BasicStateAction<S>): S {
return typeof action === 'function' ? action(state) : action;
}从源码来看 可以印证 useState只是预置了reducer的useReducer。
update时:
useReducer与useState调用的则是同一个函数updateReducer
function updateReducer<S, I, A>(
reducer: (S, A) => S,
initialArg: I,
init?: (I) => S
): [S, Dispatch<A>] {
// 获取当前hook
const hook = updateWorkInProgressHook();
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
// ...同update与updateQueue类似的更新逻辑
const dispatch: Dispatch<A> = (queue.dispatch: any);
return [hook.memoizedState, dispatch];
}这个阶段主要的作用就是 :找到与之对于的hook 然后依据update计算该hook 的新state 进行一个返回.
mount的时候 是执行的ReactDOM.render 或相关初始化API产生的更新 只会执行一次
update是在事件/副作用/render阶段产生的更新,为避免无限循环 需要区别对待
基于上面两个原因 mount是使用的是hook是 mountWorkInProgressHook,update的使用的是updateWorkInProgressHook.
接下里我们进入调用阶段,这个阶段 总结为:
创建update,将update加入queue.pending中,并开启调度。
调用阶段会执行dispactAction 此时FunctionComponnet 对应的fiber 以及hook.queue 调用bind方法预先作为参数传入。
我们通常人物 useReducer(reducer, initialState)的传参为初始化参数,在以后的调用中都不可变。
但实际情况中 在updateReducer方法中,可以看到lastRenderedReducer在每次调用时都会重新赋值。
useEffect
这个hook在 commit阶段进行,涉及到一个function flushPassiveEffects的调用
这个function会干三个事情(我们关注前两个)
- 调用该useEffect在上一次render时的销毁函数
- 调用该useEffect在本次render时的回调函数
- 如果存在同步任务,不需要等待下次事件循环的宏任务,提前执行他
我们先看第一个事情 :调用上次的销毁函数
useEffect的执行需要保证所有组件useEffect的销毁函数必须都执行完后才能执行任意一个组件的useEffect的回调函数。
// pendingPassiveHookEffectsUnmount中保存了所有需要执行销毁的useEffect
const unmountEffects = pendingPassiveHookEffectsUnmount;
pendingPassiveHookEffectsUnmount = [];
for (let i = 0; i < unmountEffects.length; i += 2) {
const effect = ((unmountEffects[i]: any): HookEffect);
const fiber = ((unmountEffects[i + 1]: any): Fiber);
const destroy = effect.destroy;
effect.destroy = undefined;
if (typeof destroy === 'function') {
// 销毁函数存在则执行
try {
destroy();
} catch (error) {
captureCommitPhaseError(fiber, error);
}
}
}
// 向pendingPassiveHookEffectsUnmount数组内push数据的操作发生在layout
// 阶段 commitLayoutEffectOnFiber方法内部的schedulePassiveEffects方法中。
function schedulePassiveEffects(finishedWork: Fiber) {
const updateQueue: FunctionComponentUpdateQueue | null = (finishedWork.updateQueue: any);
const lastEffect = updateQueue !== null ? updateQueue.lastEffect : null;
if (lastEffect !== null) {
const firstEffect = lastEffect.next;
let effect = firstEffect;
do {
const {next, tag} = effect;
if (
(tag & HookPassive) !== NoHookEffect &&
(tag & HookHasEffect) !== NoHookEffect
) {
// 向`pendingPassiveHookEffectsUnmount`数组内`push`要销毁的effect
enqueuePendingPassiveHookEffectUnmount(finishedWork, effect);
// 向`pendingPassiveHookEffectsMount`数组内`push`要执行回调的effect
enqueuePendingPassiveHookEffectMount(finishedWork, effect);
}
effect = next;
} while (effect !== firstEffect);
}
}再看第二个事情:调用本次注册的callback
与阶段一类似 也是遍历和指向effect 的回调,其中向pendingPassiveHookEffectsMount中push数据的操作同样发生在schedulePassiveEffects中。
// pendingPassiveHookEffectsMount中保存了所有需要执行回调的useEffect
const mountEffects = pendingPassiveHookEffectsMount;
pendingPassiveHookEffectsMount = [];
for (let i = 0; i < mountEffects.length; i += 2) {
const effect = ((mountEffects[i]: any): HookEffect);
const fiber = ((mountEffects[i + 1]: any): Fiber);
try {
const create = effect.create;
effect.destroy = create();
} catch (error) {
captureCommitPhaseError(fiber, error);
}
}useRef
ref有两种类型(实际上还有一种类型string 但是新版本中已经不推荐使用了,所以这里不讲了),这两种类型是 function/ { current: any }, useRef 实际上就是第二种类型
与其他hook一样,它也分mount 和 update 保存了两个不同的 dispatcher,区别就是 默认赋值 ,一个是直接获取值。
在React中 HostComponent、ClassComponent、ForwardRef(这个不会进入ref流程 它只是传递值下去,所以我们不关注)可以赋值ref属性。
HostComponent在commit阶段的mutation子阶段执行DOM操作(执行的依据就是effectTag)ClassComponnet 如果也包含ref 那么他们也会被打上对于的effectTag操作。
那么 我们就了解了:Ref 的工作可以分两个部分
- render阶段 为含有ref属性的fiber添加Ref effectTag
- commit 阶段 为包含Ref effectTag的fiber执行对应操作
render阶段
主要的事情发生咋 beginWork 与 completeWork中,他们里面都会调用 markRef方法。
下面是一些判断,符合如下条件的 fiber 会被赋值上Ref effectTag 以支持后续的工作流程
- fiber类型为HostComponent、ClassComponent、ScopeComponent(这种情况我们不讨论)
- 对于mount,workInProgress.ref !== null,即存在ref属性
- 对于update,current.ref !== workInProgress.ref,即ref属性改变
commit阶段
再具体点 它发生了 mutation 子阶段。
对于ref变化的情况 ,需要先移除之前存在的ref。
然后再进入Ref赋值阶段(Layout阶段) 调用 commitLayoutEffect会执行commitAttachRef(赋值ref)
useEffect 在源码上 实际上就在调度中对应的 schedulePassiveEffecct function的调用
useMemo和useCallback
我们还是以Mount 和Update 的两个不同的场景 来分别分析他们
function mountMemo<T>(
nextCreate: () => T,
deps: Array<mixed> | void | null,
): T {
// 创建并返回当前hook
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
// 计算value
const nextValue = nextCreate();
// 将value与deps保存在hook.memoizedState
hook.memoizedState = [nextValue, nextDeps];
return nextValue;
}
function mountCallback<T>(callback: T, deps: Array<mixed> | void | null): T {
// 创建并返回当前hook
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
// 将value与deps保存在hook.memoizedState
hook.memoizedState = [callback, nextDeps];
return callback;
}
// 这两个区别就是 是否会调用nextCreate 回调函数 然后拿值作为 value 保存 function updateMemo<T>(
nextCreate: () => T,
deps: Array<mixed> | void | null,
): T {
// 返回当前hook
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps: Array<mixed> | null = prevState[1];
// 判断update前后value是否变化
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 未变化
return prevState[0];
}
}
}
// 变化,重新计算value
const nextValue = nextCreate();
hook.memoizedState = [nextValue, nextDeps];
return nextValue;
}
function updateCallback<T>(callback: T, deps: Array<mixed> | void | null): T {
// 返回当前hook
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps: Array<mixed> | null = prevState[1];
// 判断update前后value是否变化
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 未变化
return prevState[0];
}
}
}
// 变化,将新的callback作为value
hook.memoizedState = [callback, nextDeps];
return callback;
}
// 这两个唯一的区别也是 “回调函数本身还是回调函数的执行结果作为value。”
并发更新模式Concurrent Mdode
从这里开始,有部分内容 不能通过 阅读文档来完成,需要去视频课看,属于是付费内容了,倒也是能够理解,毕竟人是要生存的,吃相不难看我能够接受。(实现异步可中断的更新)
Fiber架构的意义在于,他将单个组件作为工作单元,使以组件为粒度的“异步可中断的更新”成为可能。
们配合时间切片,就能根据宿主环境性能,为每个工作单元分配一个可运行时间,实现“异步可中断的更新”。
于是,scheduler(opens new window)(调度器)产生了。
lane模型的加入 可以明确 更新的优先级 从而提高性能。3
从源码上讲:Concurrent Mode是一套 可控的“多优先级更新架构”。
具体的上层API的表现上:batchedUpdate & Suspense & useDeferredValue
关于时间切片
scheduler这个package 上独立React 之外存在的,它的优先级 和React中的优先级并不是一个概念,这点你需要了解清楚。
scheudler主要的工作有两个方面: 时间切片/ 优先级调度。
关于时间切片的本质是模拟 requestdleCallback 。
一个task(宏任务) -- 队列中全部job(微任务) -- requestAnimationFrame -- 浏览器重排/重绘 -- requestIdleCallback唯一能够精确控制调用时机的是API是requestAnimationFrame,他能够在渲染之前调用。
退而求其次 scheduler的 时间切片是通过task完成的(MessageChannle API 比 setTime 有更高的优先级,所以在底层的实现是 能用 前者用前者不行就用setTImeOut)
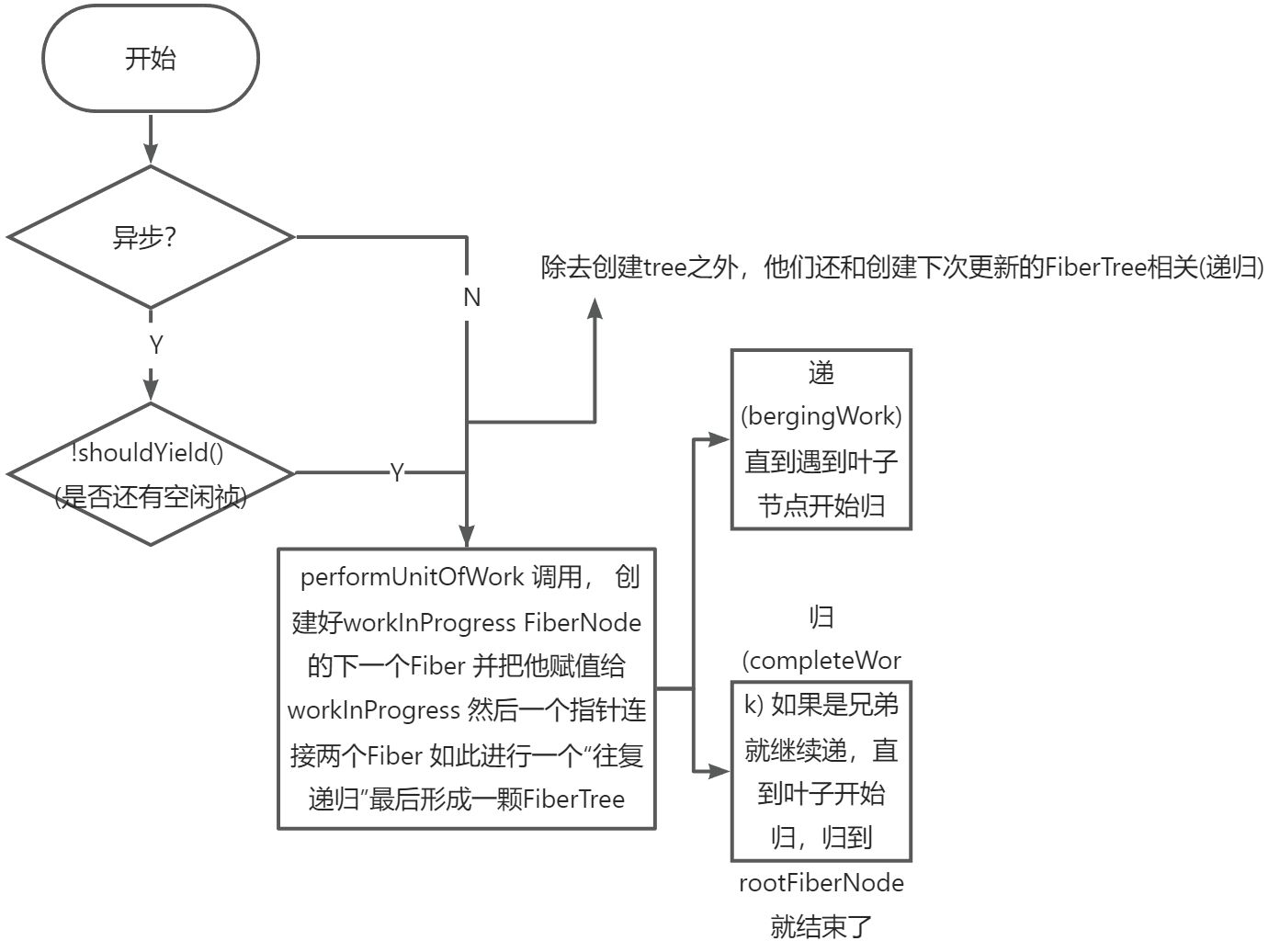
前文中提到过 react的render阶段 开启concurrent mode 遍历前 回有一个shouYeild判断,看看是否要中断 使浏览器有时间渲染。
function workLoopConcurrent() {
// Perform work until Scheduler asks us to yield
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}在Scheulder默认给每一个task分配的时间是5ms
接下来我们观察一下 performUnitOfWork被中断后是如何重新启动的。
Scheduler对外暴露了一个方法unstable_runWithPriority
这个方法接受一个优先级与一个回调函数,在回调函数内部调用获取优先级的方法都会取得第一个参数对应的优先级,有五种优先级,在react中凡涉及到 优先级的时候 都会使用这个方法。
comit是渲染的起点在comitRoot中 传递的是 ImmediateSchedulerPriority即ImmediatePriority的别名,为最高优先级,会立即执行。
除此外 shecduler 还暴露一个API unstable_schedulerCallback ,这个方法回在 优先级 中注册回掉函数。比如commit阶段的beforMuation时的useEffect 回掉
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects();
return null;
});
}不同优先级意味着不同时长的任务过期时间:
如果一个task的优先级是 Immediata的 那么对于的值 = -1 ,所以有下面的情况发生
var expirationTime = startTime - 1;则该任务的过期时间比当前时间还短,表示他已经过期了,需要立即被执行。
在react中 存在许多的优先级 task,这些任务分两类 :已准备就绪的 / 未准备就绪的,它们都保持在scheudler里
- timerQueue:保存未就绪任务
- taskQueue:保存已就绪任务
具体的调用时机是通过“小堆栈”实现的。
Lane模型
在React中会有比scheduler中更多的情况发生,所以它需要更多的设计“优先级” ,需要满足下面的要求
- 可以表示优先级的不同
- 可能同时存在几个同优先级的更新,所以还得能表示批的概念
- 方便进行优先级相关计算
对于表示优先级的不同,我们可以类比 赛车场 不同的赛道有不同的优先级。lane模型借鉴了同样的概念,使用31位的二进制表示31条赛道,位数越小的赛道优先级越高,某些相邻的赛道拥有相同优先级。
批的概念(几个变量占用了几条赛道 这就是批) 可以被称为lanes 越低优先级的更新越容易被打断,导致积压下来,所以需要更多的位。相反,最高优的同步更新的SyncLane不需要多余的lanes
关于计算的话 react使用的二进制的数据表示 所以计算也相对简单 直接位运算 就完事了。
这就是React的优先级模型lane模型。
异步的可中断更新
(有深度 后续再看)
React 18 的新特性
参考索引见这里:React18 新特性解读 & 完整版升级指南 - 掘金
我们一直都在是使用Hooks ,我们先来说一下 新增了几个hooks.
React 18 放弃了 IE11的支持,如果你还需要支持它 请切换到React 17
RenderAPI
我们可以使用 并发更新的模型了 concurrent mode,createReact(root).render , 去除了 Render的回调function 这是由于**Suspense** 会有问题,所以采取的决定
ssr时的 ,需要把hydration升级为hydrateRoot
最新的typeScirpt 支持中 对于children 这个属性 需要显示的声明(17 就不需要 默认就带)
// React 18
interface MyButtonProps {
color: string;
children?: React.ReactNode;
}setState
setState 现在可以实现 多个状态的批处理 然后一次性render了。
在17中 React 事件处理函数 中进行批处理更新,其他的是不会进行批处理的,这回导致组件过多的render,但是这种情况会有例外,比如 下面的例子会渲染两次
import React, { useState } from 'react';
// React 18
const App: React.FC = () => {
console.log('App组件渲染了!');
const [count1, setCount1] = useState(0);
const [count2, setCount2] = useState(0);
return (
<div
onClick={async () => {
await setCount1(count => count + 1);
setCount2(count => count + 1);
}}
>
<div>count1: {count1}</div>
<div>count2: {count2}</div>
</div>
);
};
export default App;
flushSync
flushSync可以让react退出批处理更新 ,flushSync 函数内部的多个 setState**** 仍然为批量更新,这样可以精准控制哪些不需要的批量更新。
React18 后你返回的空组件 不仅仅可以是null 还可以是undefined,在17中返回undefined 会导致报错
Suspense
在 React 18 的 Suspense 组件中,官方对 空的fallback 属性的处理方式做了改变:不再跳过 缺失值 或 值为null 的 fallback 的 Suspense 边界。相反,会捕获边界并且向外层查找,如果查找不到,将会把 fallback 呈现为 null。
// React 18
const App = () => {
return (
<Suspense fallback={<Loading />}> // <--- 不使用, 但是若在react 17 中那么会沿用这个
<Suspense> // <--- 这个边界被使用,将 fallback 渲染为 null
<Page />
</Suspense>
</Suspense>
);
};
export default App;
新增API
useId hook
支持同一个组件在客户端和服务端生成相同的唯一的 ID,避免 hydration 的不兼容
因为我们的服务器渲染时提供的 HTML 是无序的,useId 的原理就是每个 id 代表该组件在组件树中的层级结构。
useSyncExternalStore Hook 是一个让你订阅外部 store 的 React Hook。
能够通过强制同步更新数据让 React 组件在 CM 下安全地有效地读取外接数据源。
并发更新
useTransition hook的使用会 引起并发更新,
startTransition,主要为了能在大量的任务下也能保持 UI 响应。这个新的 API 可以通过将特定更新标记为“过渡”来显著改善用户交互,简单来说,就是被 startTransition 回调包裹的 setState 触发的渲染被标记为不紧急渲染,这些渲染可能被其他紧急渲染所抢占。
与之类似的还有一个hook 叫做 useDeferredValue ,可以让一个state 延迟生效,只有当前没有紧急更新时,该值才会变为最新值。
与 useTransition 的区别如下:
- 相同:useDeferredValue 本质上和内部实现与 useTransition 一样,都是标记成了延迟更新任务。
- 不同:useTransition 是把更新任务变成了延迟更新任务,而 useDeferredValue 是产生一个新的值,这个值作为延时状态。(一个用来包装方法,一个用来包装值)